Trisul EDGE – streaming graph analytics for Network Security Monitoring
Trisul EDGE is the graph analysis feature in the latest version of Trisul Network Analytics. We believe it will take your deep network based security monitoring to the next level. Here is a technical feature brief.
One of the first questions analysts tend to ask when confronted with an event or an unexpected entity is “what else is related to this?”
This type of query is astonishingly hard to answer in near real time if you havent already enriched your data to prepare for this. The data enrichment phase can be seen in typical Logstash configs in ELK Pipelines. They work well for small number of extra attributes of tags. Anything beyond that will need large cluster rollout that isnt practical for our target users – security conscious organisations with limited budgets.
Typical use case
Here is an illustration. Say you are tracking the metric group TLS Certificate Authorities and stumble upon a newly seen Intermediate CA TubeMogul . Where do you go from here? Here are some questions you might ask
- which TLS Organizations used this as an Issuer?
- which internal and external IPs and hostnames accessed resources?
- which country (Geo) attributes
- which application
- etc : any other types of connections you dont even know exist

Without graph analytics, you would have to enrich each type of data attribute with every other type. This is what some search based solutions do with the ELK stack or Splunk. Even the streaming based platforms like Apache Metron use an enrichment phase after the parsing phase. However we think a graph analytics is a better fit for exploring relationships that are in the network traffic itself or discovered by other stages of the streaming pipeline.
With the new Trisul EDGE features, all you do is to select the “View Edge Graph” menu item. This opens the subset of the graph with the selected item as the root vertex. Trisul EDGE only selects the edges that were active in the selected time interval and presents you a sub-graph that was relevant in that interval. This is a major difference of our streaming graph analytics approach versus static graph databases.
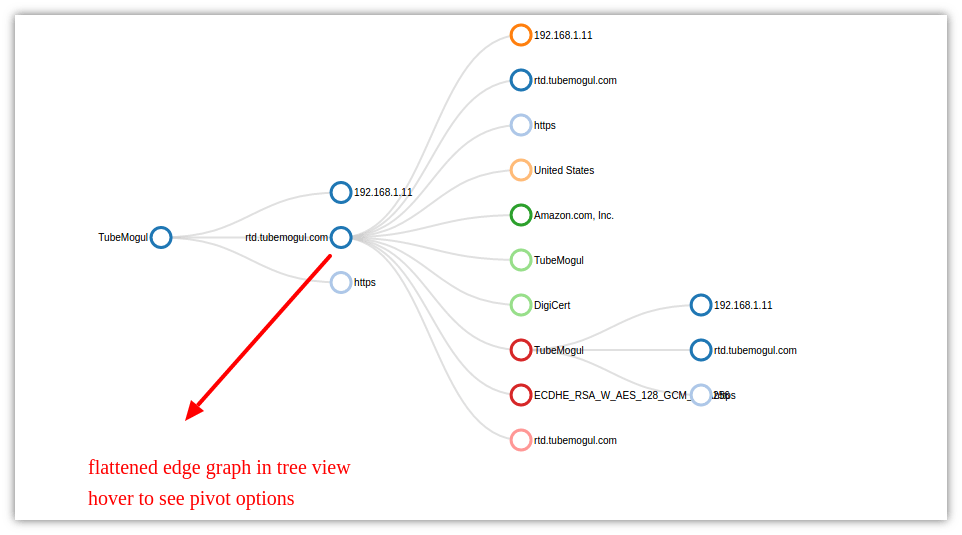
The following image shows the Edge graph explorer with the root node TubeMogul on the far right and adjacent vertices. We have also expanded an adjacent vertex TLS host rtd.tubemogul.com to reveal its adjacencies as well. You can click through and expand the graph into any direction you want one adjacency at a time.
In the chart :
- each vertex is color coded to reflect a certain data-type Put your mouse over the vertex to reveal the type.
- in the chart the vertices are from counter groups TLS Cert Authorities, Cipher Suites, Internal and External Hosts, Host names, Country , AS Number
- click on any vertex to open up its adjacencies.
- hover to access further Pivot and Drilldown options

If this layout is too cluttered you can selected “Tree view” to work with the flattened tree version of this

Making this practical to deploy
When your network monitoring approach is to extract all kinds of meta information – the volume and velocity of data just explodes. Even relatively small organizations with < 1Gbps of traffic can generate streams rivaling large internet companies document based workloads. Deploying a real lossless big data platform to consume this can be a huge undertaking for our target customers which are security conscious orgs with limited budget.
Trisul EDGE takes several trimming measures that enable consumption of a high velocity stream of “edge updates” with modest memory and CPU resources. The goal here is to cap memory usage and completion of graph updates within a time budget dictated by the streaming window. Most of our techniques are based on tracking cardinality of vertices. We find that much of security related analysis demands tracking low cardinality vertices (rarely seen things) rather than high cardinality ones. Here are some things we do.
- Memory cap : For a given vertex we impose a 1K memory cap on number of allowed edges per type.
- High cardinality cut off : Trim edges of very high cardinality vertices. Use the First-K instead of Top-K to further reduce memory use.
- No weights to edges : All edges are of equal weight and are un-directed.
- Skip very high cardinality entirely : An illustration : we dont introduce “TCP” as a vertex at all because of the unnecessary costs such a high cardinality item would introduce to the graph. This is an optimization we can leverage because we dont think “I want to see relationships to TCP protocol” as a query that will be asked.
- Other optmizations : In other places we prefer realtime-but-approximate slow-but-100%-accurate.
These optimizations allow us to bring such an advanced analytical capability to maintenance free single box deployments of Trisul in orgs who do not have the budget or the stomach for managing typical Big Data clusters. We will expand on these in later technical posts.
Go and FREE download our latest release today to start discovering the benefits. Advanced adopters please contact us for an extended license, we would love to hear more about how our optimization settngs work for various workloads.For Documentation on enabling Trisul EDGE on existing deployments. See the Trisul EDGE User Guide Docs

Free Download Trisul 6.0 ! Ready to go packages for Ubuntu and CentOS.